 Redis简介
Redis简介
# Redis简介
Redis是一个开源的内存数据结构存储系统。提供了多种数据类型来支持不同的业务场景,Redis广泛用于各种应用程序,例如缓存、实时分析、消息系统、任务队列等。
# 数据类型
# 常见的数据类型
# String(字符串)
最基本的key-value结构,key是唯一标识,value是具体的值(字符串、整数、浮点数)。
结构
key: value
# String(字符串)
RBucket<Object> bucket = redissonClient.getBucket("str-key", new StringCodec("utf-8"));
bucket.set("str1");
log.info("字符串str-key:{}", bucket.get()); # 字符串str-key:str1
# JSON字符串
RBucket<Object> bucket2 = redissonClient.getBucket("str-key2", new StringCodec("utf-8"));
Student student = new Student("张三");
bucket2.set(JSON.toJSONString(student));
log.info("JSON字符串str-key2:{}", bucket2.get()); # JSON字符串str-key2:{"name":"张三"}
2
3
4
5
6
7
8
9
10
11
# Hash(哈希)
键值对集合。
结构
key : [{ key1:value1 }, { key2:value2 }, ...]
# 哈希
RMap<Object, Object> map = redissonClient.getMap("map", new StringCodec("utf-8"));
map.put("name", "mike");
map.put("name2", "jack");
log.info("哈希map:{}", map.get("name")); # 哈希map:mike
2
3
4
5
# List(列表)
是简单的字符串列表。
结构
key : [ {key1:value1, key2:value2,...}, {}, ... ]
# 列表
RList<Object> list = redissonClient.getList("list", new StringCodec("utf-8"));
Student student = new Student("张三");
Student student2 = new Student("李四");
list.add(student);
list.add(student2);
log.info("列表:{}", list.readAll()); # 列表:[RedisController.Student(name=张三), RedisController.Student(name=李四)]
2
3
4
5
6
7
8
# Set(集合)
无序并唯一的键值集合,与list列表类似,自动去重。
结构
key : [ {key1:value1, key2:value2,...}, {}, ... ]
# 集合
RSet<Object> set = redissonClient.getSet("setKey", new StringCodec("utf-8"));
Student student = new Student("张三");
set.add(student);
log.info("集合:{}", set.readAll()); # 集合:[RedisController.Student(name=张三)]
2
3
4
5
# Zset(有序集合)
有序集合,比Set类型多了一个排序属性score。
结构
key : [ {key1:value1, key2:value2,...}, {}, ... ]
# 有序集合
RScoredSortedSet<Object> sortedSet = redissonClient.getScoredSortedSet("zSetKey", new StringCodec("utf-8"));
Student student = new Student("张三");
Student student2 = new Student("李四");
sortedSet.add(3.0, student);
sortedSet.add(2.0, student2);
log.info("有序集合:{}", sortedSet.readAll()); # 有序集合:[RedisController.Student(name=李四), RedisController.Student(name=张三)]
2
3
4
5
6
7
# 其它数据类型
# BitMap
位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。使用它进行储存将非常节省空间,特别适合一些数据量大且使用二值统计的场景。
# HyperLogLog
HyperLogLog 提供不精确的去重计数。是一种用于统计一个集合中不重复的元素个数。但要注意,HyperLogLog 是统计规则是基于概率完成的,不是非常准确,标准误算率是 0.81%。
# GEO
用于存储地理位置信息,并对存储的信息进行操作。GEO非常适合应用在 LBS(基于位置信息服务) 的场景中。
# Stream
为消息队列设计的数据类型。
# 缓存设计
# 缓存雪崩
为了保证缓存中的数据与数据库中的数据一致性,会给 Redis 里的数据设置过期时间,当缓存数据过期后,用户访问数据时就会去访问数据库,并将数据更新到 Redis 里,这样后续请求就可以从缓存中获取。
当大量缓存数据在同一时间过期(失效)时,如果此时有大量的用户请求,都无法从缓存中获取,全部请求都直接访问数据库,从而导致数据库的压力骤增,严重的会造成数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃,这就是缓存雪崩。
解决方案
- 分散缓存失效时间,降低缓存集体失效的概率。
- 设置缓存不过期,通过后台服务更新缓存,避免因为缓存失效造成的缓存雪崩。
# 缓存击穿
如果缓存中的某个热点数据(秒杀活动)过期了,此时大量的请求无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮,这就是缓存击穿。
可以发现缓存击穿跟缓存雪崩很相似,可以认为缓存击穿是缓存雪崩的一个子集。 应对缓存击穿可以采取前面说到两种方案:
- 互斥锁方案,保证同一时间只有一个业务线程请求缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。
- 热点数据不设置过期时间,由后台更新缓存,或者在热点数据过期前,通知后台线程更新缓存以及重新设置过期时间。
# 缓存穿透
当用户访问的数据,既不在缓存中,也不在数据库中,没办法构建缓存数据,来服务后续的请求。那么当有大量这样的请求到来时,数据库的压力骤增,这就是缓存穿透。
缓存穿透一般产生的情况,1.误操作,缓存和数据库中的数据都被删除;2.恶意攻击,故意大量访问不存在数据的业务。
解决方案
- 限制非法请求,在API入口处校验参数。
- 设置空值或者默认值,请求就可以从缓存中读取到空值或者默认值,返回给应用,而不会继续查询数据库。
- 布隆过滤器,缓存失效后,先查询布隆过滤器快速判断数据是否存在,即使发生了缓存穿透,大量请求只会查询 Redis 和布隆过滤器,保证了数据库能正常运行,Redis也支持布隆过滤器。
# 数据一致性
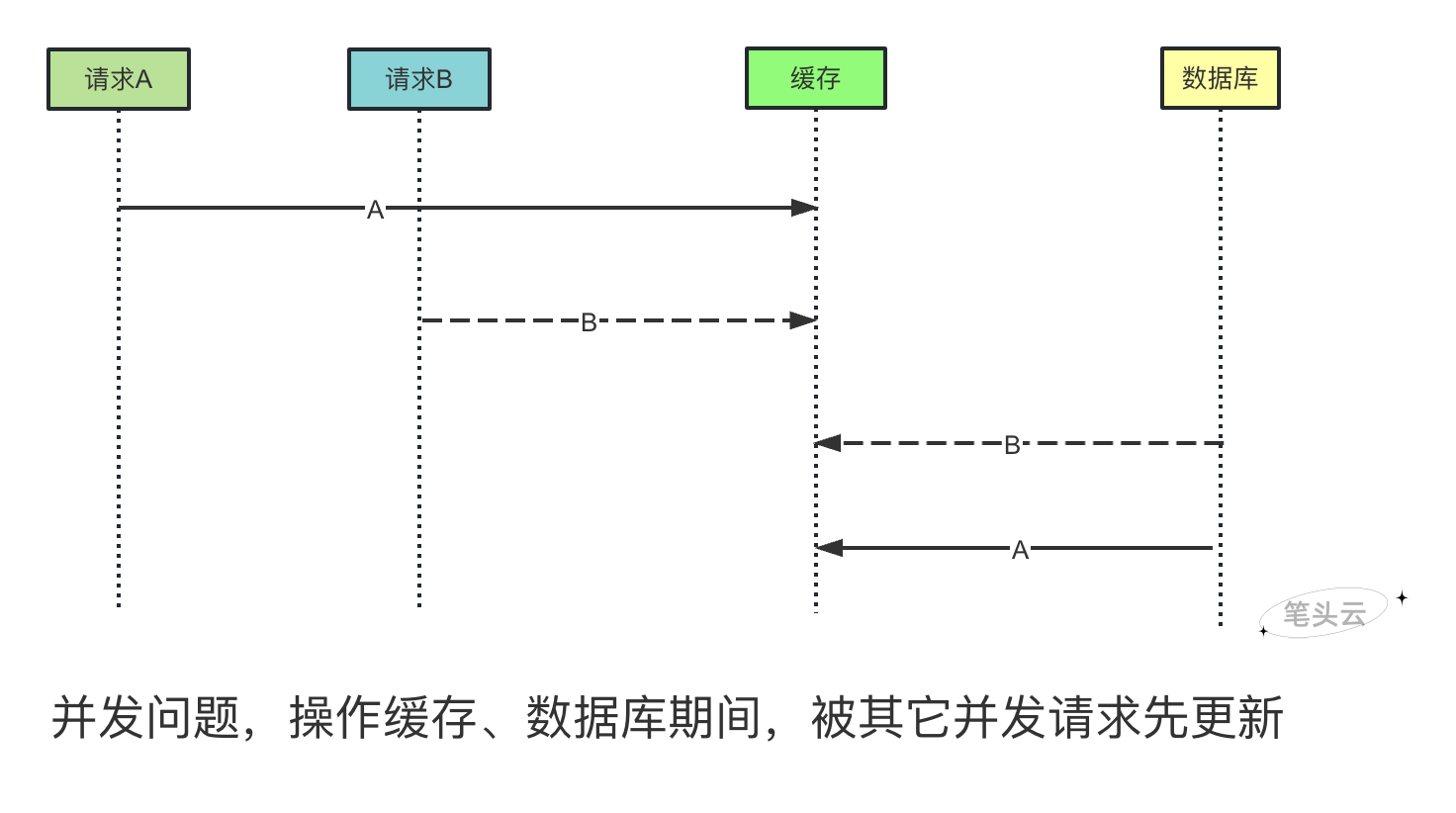
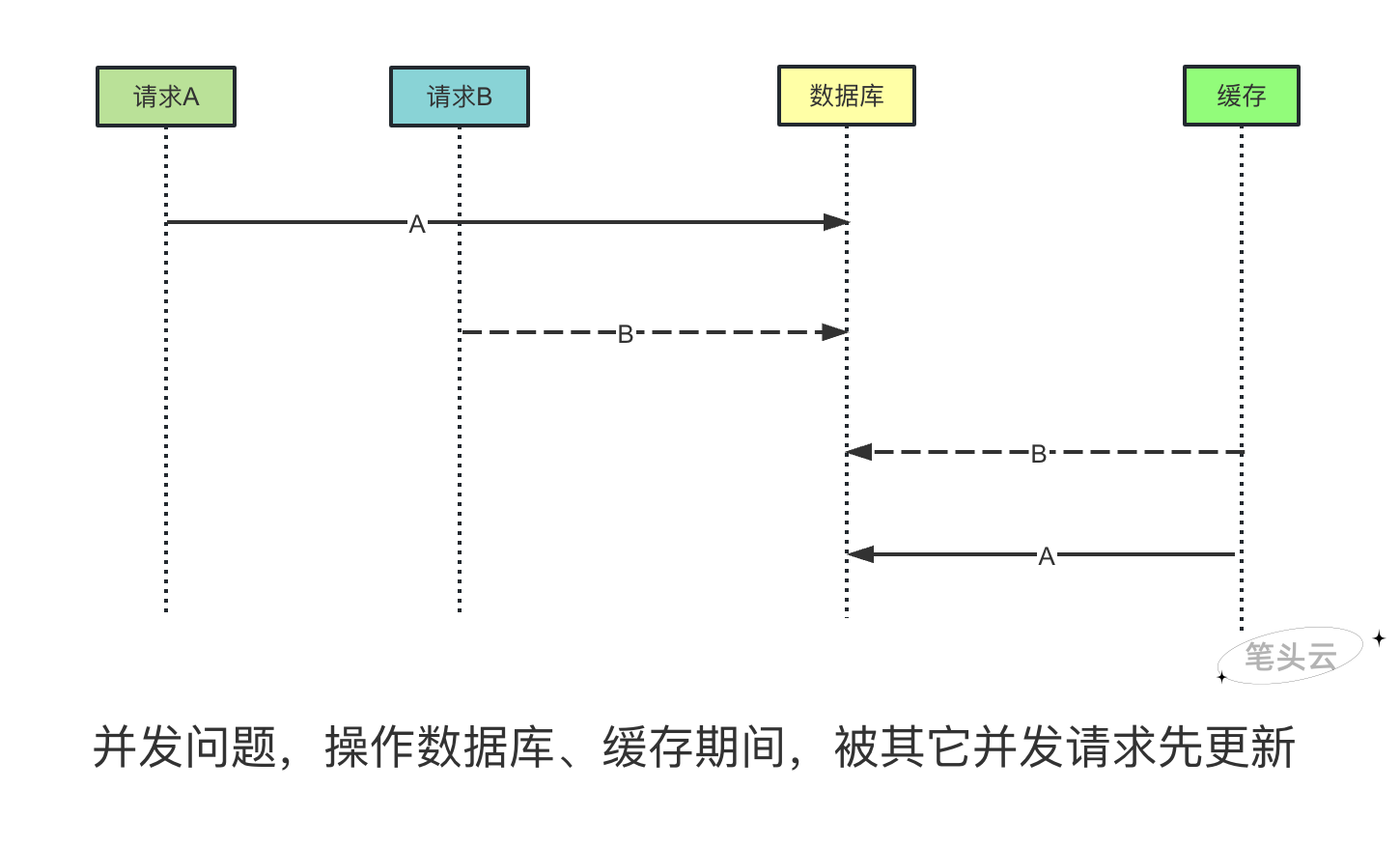
- img: https://bitouyun.com/images/redis/redis-1.png
link: https://bitouyun.com/images/redis/redis-1.png
name: 数据一致性问题
- img: https://bitouyun.com/images/redis/redis-2.png
link: https://bitouyun.com/images/redis/redis-2.png
name: 数据一致性问题
2
3
4
5
6
# 解决方案
- 先更新数据库,后删除缓存,给缓存设置失效时间。要确保更新数据、删除缓存都成功。 可以将删除缓存操作放入消息队列中,如果删除失败,会再次删除(重试机制)。
- 为了提高缓存命中率,先更新数据库,后更新缓存,给缓存设置失效时间,更新缓存前加分布式锁,解决并发问题。
# 数据库、缓存操作顺序
无论先操作数据库还是缓存,都存在并发问题,但是删除缓存操作比更新缓存更轻量(更新数据可能业务逻辑比较复杂),操作缓存比操作数据库耗时短,因此先操作数据库,后删除缓存比较合理(更新完数据库到删除缓存之间的耗时短)。
- 先操作数据库后操作缓存,存在并发问题,更新数据库时间比更新缓存时间慢,在A请求更新数据库后,更新缓存前,B请求更新数据库和缓存,然后A请求再更新缓存,导致缓存跟数据库数据不一致(B请求的数据为最新值)。
- 先操作缓存后操作数据库,存在并发问题,在A请求更新缓存后,更新数据库前,B请求更新缓存和数据库后,A请求再更新数据库,导致缓存跟数据库不一致(B请求的数据为最新值)。
- 02
- 在线时间戳转换工具 - Unix时间戳与日期互转04-07
- 03
- 在线Base64编解码工具 - 文本与Base64互转04-07